
Büyük ölçekli bir tablodan bir veriyi bulmak için tüm satırlarda o veriyi aramanız, bulduğunuzda da aynı veriden başka var mı diye sona kadar gitmeniz gerekir. Sql Server Clustered ve Non-Clustered Indexler bu noktada yardımımıza koşuyor.
Küçük ya da büyük ölçekte bir veritabanı oluştumuşsanız tablolarınızda bir kolona primary key ataması yapmışsınızdır. Bu atama o kolon için aynı zamanda bir index oluşturuyor. FindById gibi standart fonksiyonlarda bu index’li alanda arama yaptığı için oldukça hızlı dönebiliyor.
Clustered Index
Clustered Index’ler, kitaplarda bulunan içindekiler gibi davranan yapılardır. Bir kitap yazılırken başlıklar belirli bir sıraya göre sıralanır, yeni bir konu eklenecekse, bu sıradaki uygun yeri bulunup oraya eklenir. Clustered index’te aynı şekilde davranır. Tabloya veri eklerken, sql server tablonun clustered index’ine bakar ve bu index’in sırasına göre yerleşim yapar. Daha somut bir örnek ile gösterelim:
Ağdaki printer’ları tutan bir tablo yaratalım.
create table [tblPrinter] ( [Id] int primary key, [Brand] nvarchar(100), [Ip] nvarchar(20), [printOutCount] int, [cDate] datetime )
Primary key olarak tanımlı Id alanı default olarak Clustered Index olarak atanacaktır. Kontrol edelim:
execute sp_helpindex tblPrinter
Çıktısı: 
Görüldüğü gibi id alanı index ve primary olarak işaretlendi.
Şimdi bu tabloya bir kaç satır girelim. Girilen satırların id alanının rastgele olduğuna dikkat edin.
insert into tblPrinter Values (4,'Canon','192.168.1.36',400,GETDATE()) insert into tblPrinter Values (2,'Xerox','192.168.1.55',200,GETDATE()) insert into tblPrinter Values (5,'Xerox','192.168.1.51',450,GETDATE()) insert into tblPrinter Values (1,'HP','192.168.1.39',700,GETDATE()) insert into tblPrinter Values (6,'Canon','192.168.1.68',150,GETDATE()) insert into tblPrinter Values (3,'Canon','192.168.1.58',100,GETDATE())
Girilen satırları çekelim:
select * from tblPrinter
Çıktısı :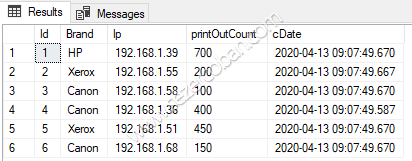
Görüldüğü gibi, insert statement’larımızda id değerlerini rastgele-sırasız vermemize rağmen, sql bunları cluster index tanımlı id’ye göre sıralayarak ekledi. Id alanına göre bir sorgu yaptığımızda kümelenmiş(clustered) tablo içerisinden performanslı ve hızlı bir şekilde satırları getirecektir.
Composite Clustered Index
Bir tablo da sadece bir tane clustered index yapısı tanımlanabiliyor. Fakat bu tanımlamada, birden fazla kolon’a göre iç içe dizilim gerçekleştirebiliriz. Öncelikle varolan tablomuzdaki indexi silelim. Bunun için sqlserver management studio’dan tablo altında indexes klasörü içerisinden silebilir yada drop index komutu ile indexi kaldırabiliriz.
Yeni bir index ekleyelim:
Create clustered index IX_tblPrinter_name_count on tblPrinter(Brand ASC, printOutCount Desc)
Tablomuza IX_tblPrinter_name_count adında bir index ekledik, bu index; önce Brand kolonunu artan sıralamada, sonra printOutCount kolonunu azalan sıralamada kümelendirecek. Select sorgumuzu tekrar çağıralım:
select * from tblPrinter
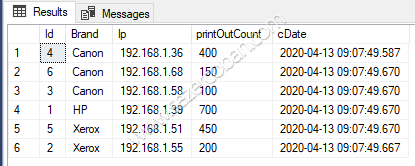
Görüldüğü gibi, sorgu önce brand’ları bir araya topladı, topladığı Brand’lar içerisinde ise printOutCount’a göre azalan bir composite index oluşturmuş oldu.
Non-Clustered Index
Non-clustered index, pointer mantığı ile çalışan, oluşturulan her non-clustered index kolonu için ayrı bir depolama alanı açıp, kolondaki verilerin hangi satırda olduğu belirten bir yapı oluşturur. Bu kolondan bir veri çekilmek istendiğinde ise, bu yapıdan yeri sorulurarak, tablomuzdaki satıra doğrudan gider.
Non-clustered index, genelde kitap sonlarındaki konuya göre sayfa numarasına benzetilir. Kitapta bir konu üzerindeki sayfaları bir arada veren(doğrudan nokta atışı yapan) sayfalar gibi, non-clustered indexlerde doğrudan satır numarasını verir.
Yukarıdaki örnekte, tblPrinter tablosunda, id’yi index yaptık diyelim ve id üzerinden bir çok yerde sorgu yapıyoruz ve işimizi görüyor. Ya belirli bir cdate ye göre çağırma yapmak istersek? Sorgumuz tüm tablodaki cdate alanlarına bakacak, bitirdikten sonra bize dönüş yapacak. İşte tam bu noktada non-clustered index devreye giriyor ve diyor ki: aradığınız tarih X numaralı satırda.
Sql Server üzerinde non-clustered index oluşturmak için;
create nonclustered Index IX_tblPrinter_cdate on tblPrinter(cdate)
komutunu çağırıyoruz. helpindex ile sorguladığımızda;

Eklendiğini görebiliyoruz.
Bir kaç önemli nokta:
- Bir tabloda sadce 1 tane clustered index olabilirken, 999 adete kadar non-clustered index eklenebilir.
- Clustered index’ler non-clustered index’lere göre daha hızlıdır.
- Clustered index’ler depolamanın sıralamasını tutar. Ekstra bir depolama alanına ihtiyaç duymazlar. Non-clustered indexler ayrı bir tablo yapısında tuttuğu için ekstra alana ihtiyaç duyarlar.
Sonuç olarak, Sql Server Clustered ve Non-Clustered Indexler; Sql server normalizasyon konusu ile iç içe bir konu. İhtiyacınız dahilinde performans optimizasyonu için gerekli yapılar. Tablo büyüklüğü ve yazılım mimariniz ile hangilerinin kullanılacağına karar verilmesi gerekir.